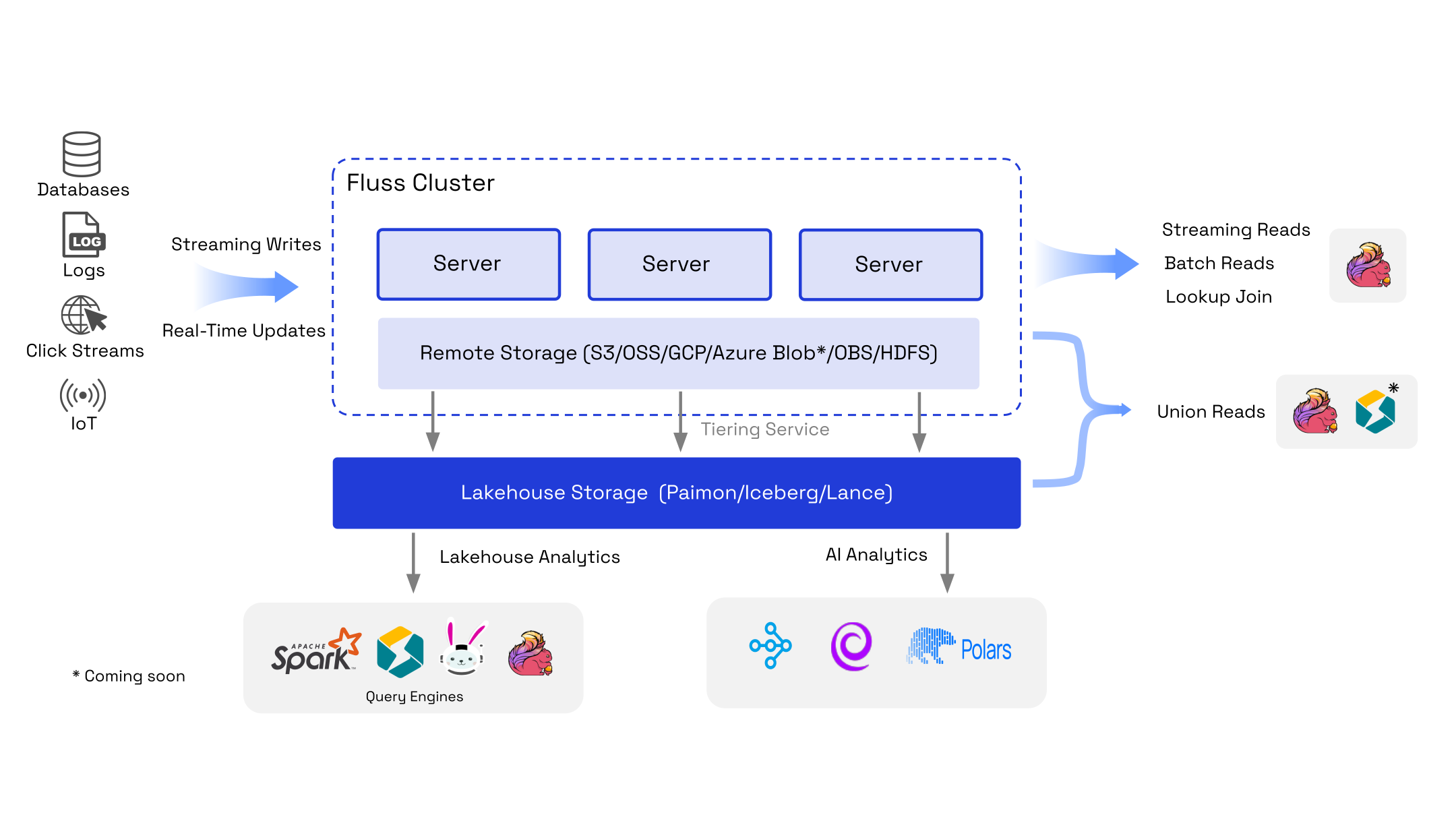
Apache Fluss (Incubating) is a streaming storage built for real-time analytics & AI which can serve as the real-time data layer for Lakehouse architectures. With its columnar stream and real-time update capabilities, Fluss integrates seamlessly with Apache Flink to enable high-throughput, low-latency, cost-effective streaming data warehouses tailored for real-time applications.
Key Features
Sub-Second Data Freshness
Continuous ingestion and immediate availability of data enable low-latency analytics and real-time decision-making at scale.
Streaming & Lakehouse Unification
Streaming-native storage with low-latency access on top of the lakehouse, using tables as a single abstraction to unify real-time and historical data across engines.
Columnar Streaming
Based on Apache Arrow it allows database primitives on data streams and techniques like column pruning and predicate pushdown. This ensures engines read only the data they need, minimizing I/O and network costs.
Compute–Storage Separation
Stream processors focus on pure computation while Fluss manages state and storage, with features like deduplication, partial updates, delta joins, and aggregation merge engines.
ML & AI–Ready Storage
A unified storage layer supporting row-based, columnar, vector, and multi-modal data, enabling real-time feature stores and a centralized data repository for ML and AI systems.
Changelogs & Decision Tracking
Built-in changelog generation provides an append-only history of state and decision evolution, enabling auditing, reproducibility, and deep system observability.