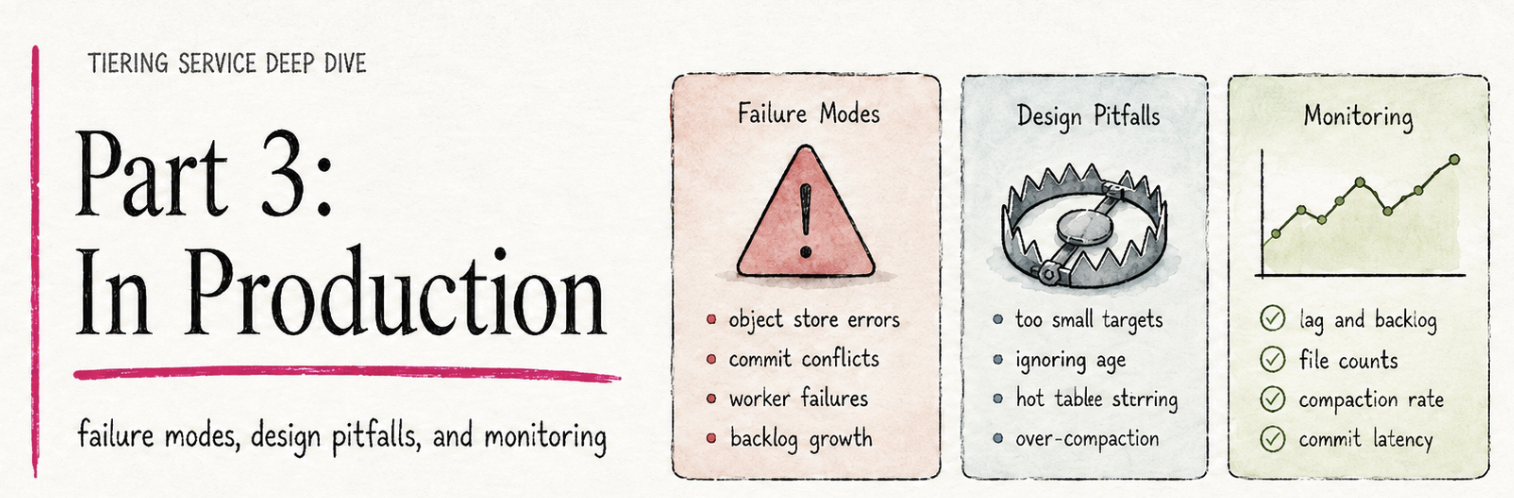
Tiering Service Deep Dive Part 3: In Production

Part 1 and Part 2 built up everything you need to know about how tiering behaves: the mental model, the dials, the queue dynamics, the scale-out story. This part is about what to do with all of that. What breaks at runtime, and which of those failures self-heal versus need operator action. The design mistakes that look fine on day one but come back to bite you on day two. And the operator's daily view: which five numbers tell you whether tiering is healthy on a Tuesday afternoon, where each one comes from, and why two of them can only come from your Flink-side dashboards.
Tiering Service Deep Dive, 3-parts:
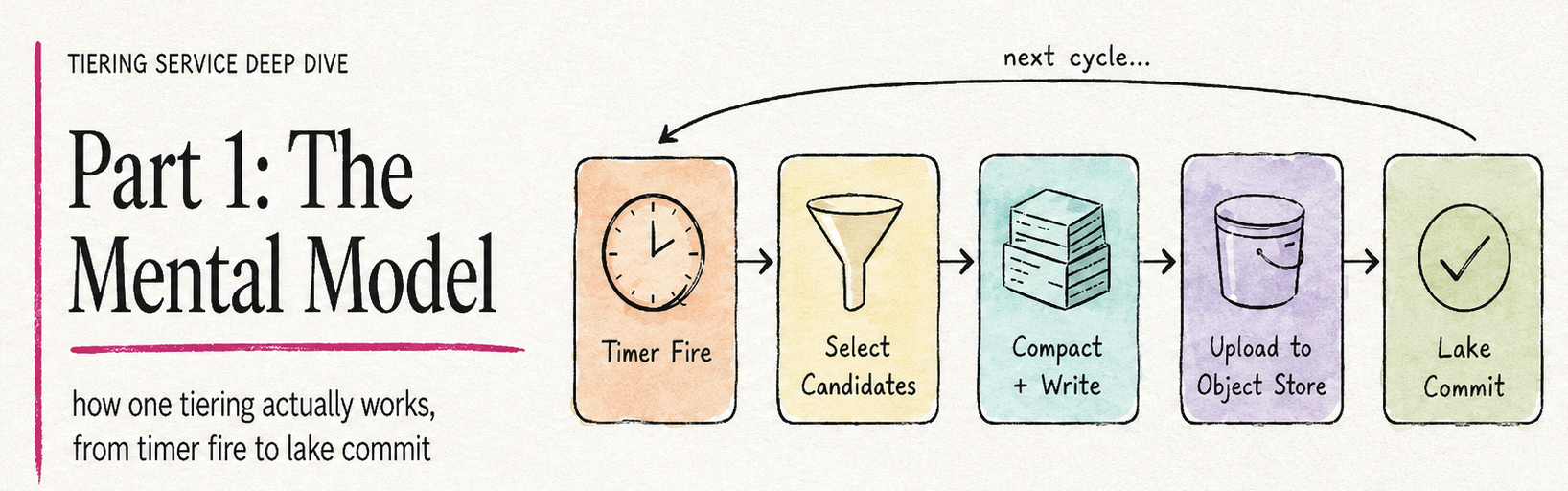
- Part 1 - The Mental Model: how one tiering round actually works, from timer fire to lake commit.
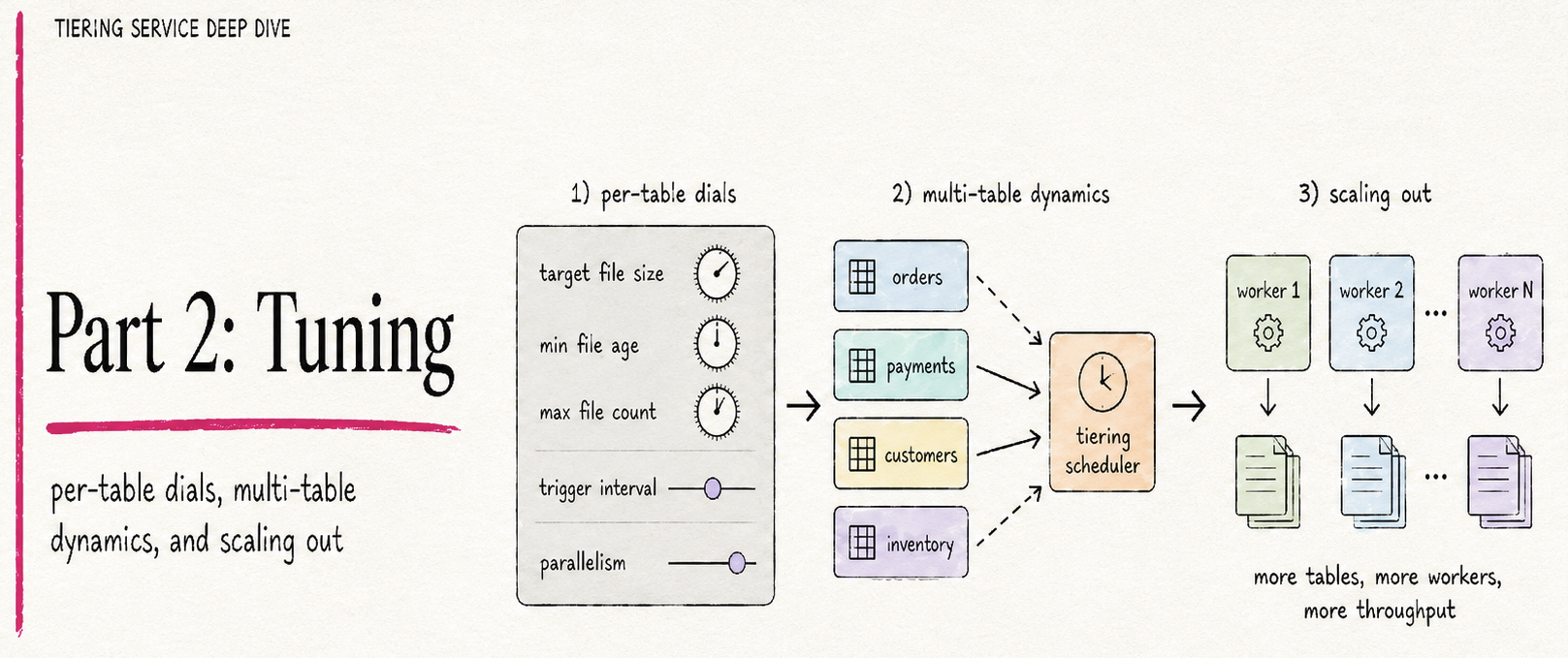
- Part 2 - Tuning: per-table dials, multi-table dynamics, and scaling out.
- Part 3 - In Production: failure modes, design pitfalls, and the dashboard that tells you everything is fine.
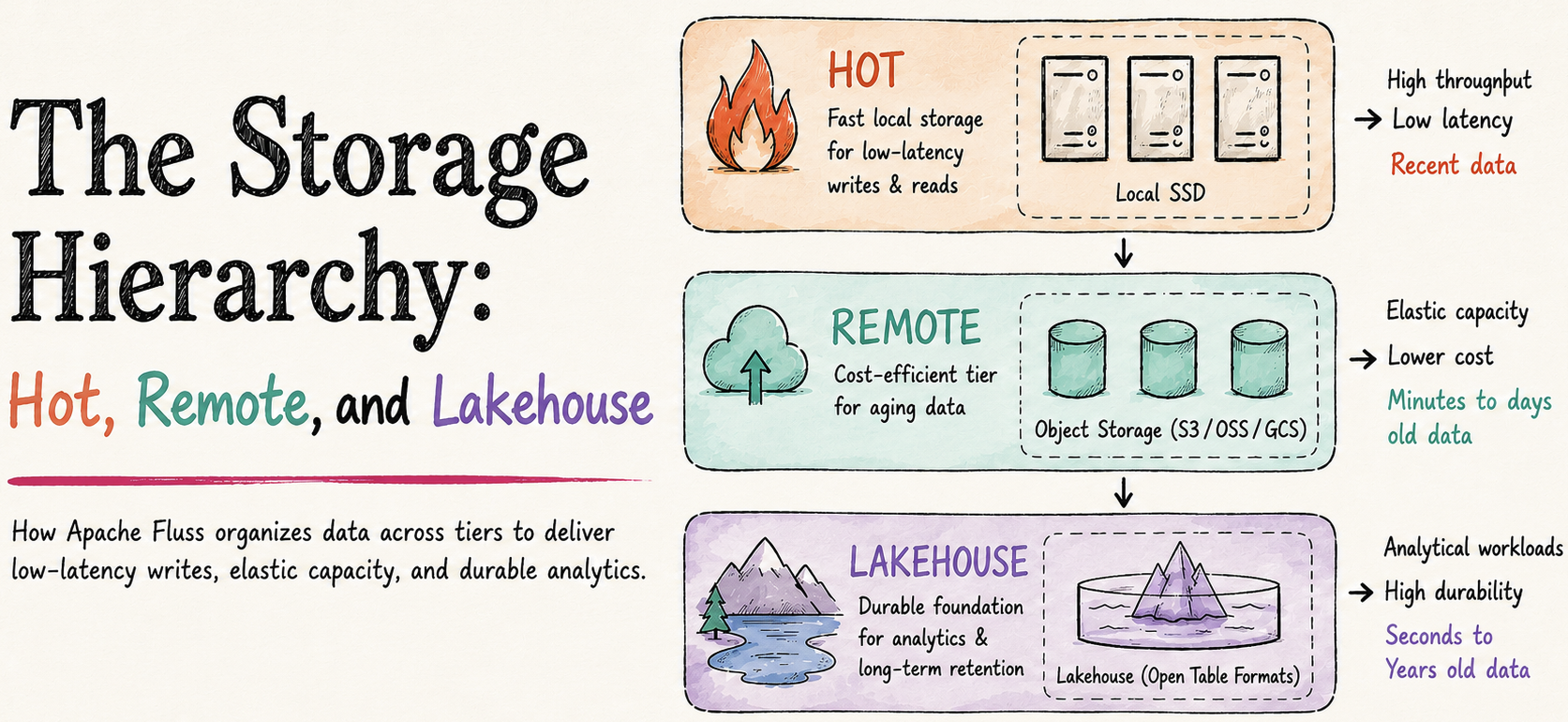









 Apache Fluss (Incubating) started as streaming storage for real-time analytics, built to work closely with stream processors like Apache Flink.
Its focus has always been on freshness, efficient analytical access, and continuous data, making fast-changing streams directly usable without forcing them
through batch-oriented systems or log-only pipelines.
Apache Fluss (Incubating) started as streaming storage for real-time analytics, built to work closely with stream processors like Apache Flink.
Its focus has always been on freshness, efficient analytical access, and continuous data, making fast-changing streams directly usable without forcing them
through batch-oriented systems or log-only pipelines.