What does Apache Fluss mean in the context of AI?

The Data Foundation for Real-Time Intelligent Systems
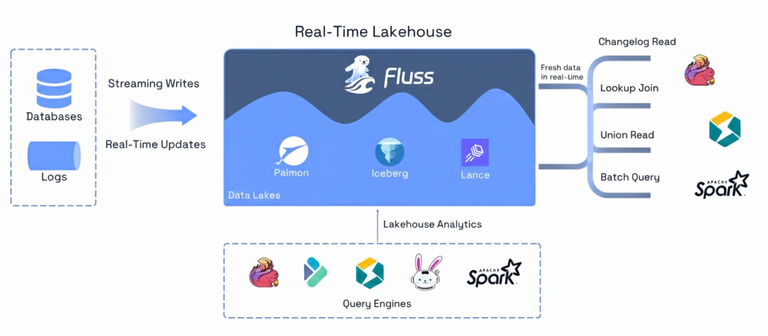
 Apache Fluss (Incubating) started as streaming storage for real-time analytics, built to work closely with stream processors like Apache Flink.
Its focus has always been on freshness, efficient analytical access, and continuous data, making fast-changing streams directly usable without forcing them
through batch-oriented systems or log-only pipelines.
Apache Fluss (Incubating) started as streaming storage for real-time analytics, built to work closely with stream processors like Apache Flink.
Its focus has always been on freshness, efficient analytical access, and continuous data, making fast-changing streams directly usable without forcing them
through batch-oriented systems or log-only pipelines.
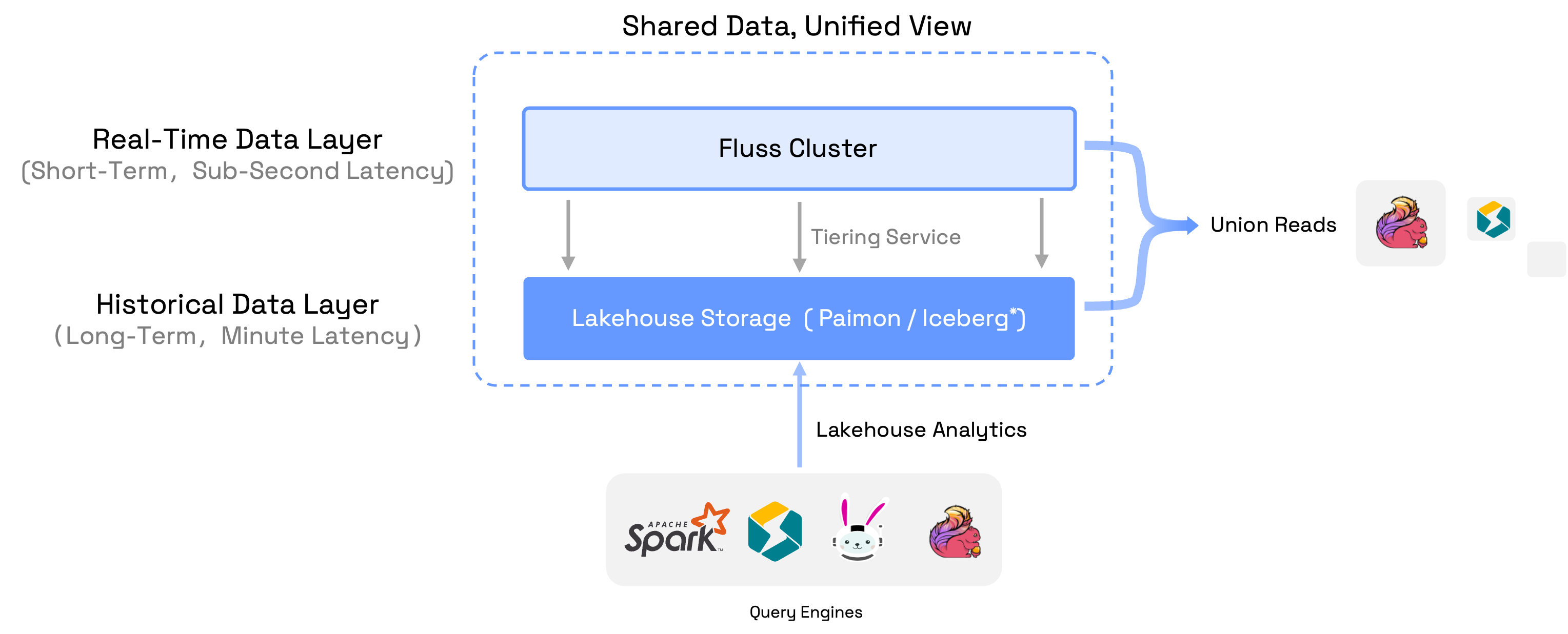
Over the last year, Fluss has expanded beyond this original framing. You’ll now see it described as streaming storage for real-time analytics and AI. This change reflects how data systems are being used today: more workloads depend on continuously updated data, low-latency access to evolving state, and the ability to reason over context as it changes.
In this context, “AI” does not mean training or serving models inside Fluss. It refers to the class of intelligent systems that rely on fresh features, evolving context, and real-time state to make decisions continuously. Whether those systems use traditional machine learning models, newer AI techniques, or a combination of both, they all depend on the same data foundations.
This shift explains the recent evolution of Apache Fluss. Investments in stateless compute, richer data types with zero-copy schema evolution, and vector support through Lance were driven by a single question:
What does a data foundation need to look like to support real-time intelligent systems reliably at scale?
The rest of this post answers that question. We’ll explain what AI means when viewed through the lens of Apache Fluss, and why a streaming-first foundation for features, context, and state is central to building the next generation of intelligent systems.