What is Fluss?
Fluss is a streaming storage built for real-time analytics & AI which can serve as the real-time data layer for Lakehouse architectures.
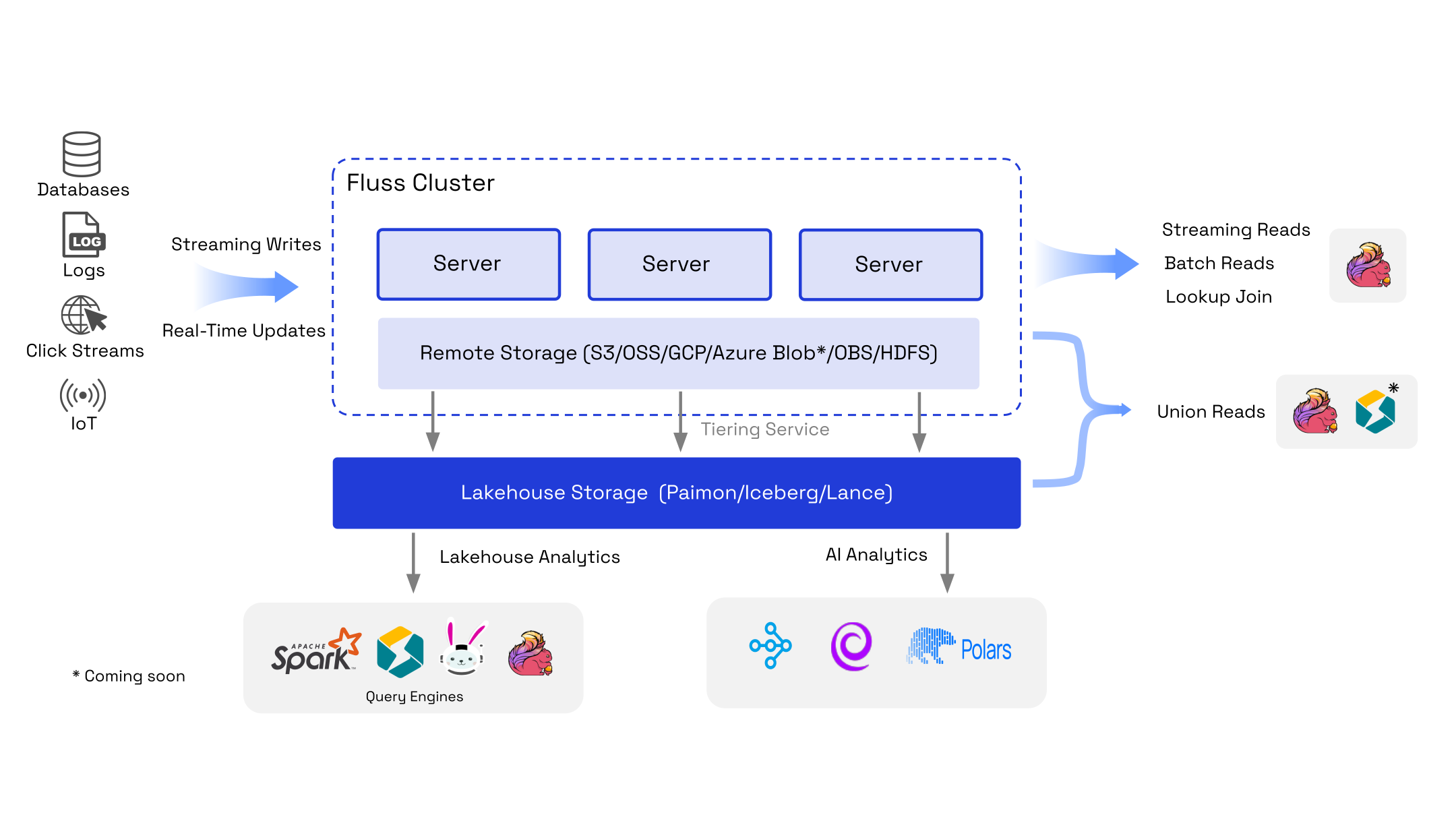
It bridges the gap between streaming data and the data Lakehouse by enabling low-latency, high-throughput data ingestion and processing while seamlessly integrating with popular compute engines like Apache Flink, with Apache Spark and StarRocks coming soon.
Fluss supports streaming reads and writes with sub-second latency and stores data in a columnar format, enhancing query performance and reducing storage costs.
It offers flexible table types, including append-only Log Tables and updatable PrimaryKey Tables, to accommodate diverse real-time analytics and processing needs.
With built-in replication for fault tolerance, horizontal scalability, and advanced features like high-QPS lookup joins and bulk read/write operations, Fluss is ideal for powering real-time analytics, AI/ML pipelines, and streaming data warehouses.
Fluss (German: river, pronounced /flus/) enables streaming data continuously converging, distributing and flowing into lakes, like a river 🌊
Use Cases
The following is a list of (but not limited to) use-cases that Fluss shines ✨:
- 📊 Optimized Real-time analytics
- 🔧 Feature Stores
- 📈 Real-time Dashboards
- 🧍 Real-time Customer 360
- 📡 Real-time IoT Pipelines
- 🚓 Real-time Fraud Detection
- 🚨 Real-time Alerting Systems
- 💫 Real-time ETL/Data Warehouses
- 🌐 Real-time Geolocation Services
- 🚚 Real-time Shipment Update Tracking
Where to go Next?
- QuickStart: Get started with Fluss in minutes.
- Architecture: Learn about Fluss's architecture.
- Table Design: Explore Fluss's table types, partitions and buckets.
- Lakehouse: Integrate Fluss with your Lakehouse to bring low-latency data to your Lakehouse analytics.
- Development: Set up your development environment and contribute to the community.